最近在学习图数据库的基础知识。本文将参考 《Learning SPARQL: querying and updating with SPARQL 1.1》这本书,简单介绍图数据的数据模型 RDF。主要内容如下:
- RDF 简介
- RDF 三元组
- RDF 存储格式
- RDF 其他概念
RDF 简介
RDF 全称 Resource Description Framework(资源描述框架),是一种数据模型,它提供了一种独特的结构来存储数据文件。RDF 独特的结构使其在 Semantic Web、图数据库等领域应用十分广泛。
基本格式
在 RDF 中,每一个基本单元可由一个三元组 \((s,\ p,\ o)\) 构成,其中 \(s\) 代表 subject(主语),\(p\) 代表 predicate(谓语), \(o\) 代表 object(宾语)。每一个三元组都可以陈述这样一个事实:一个由 \(s\) 唯一标记的资源实体拥有 \(p\) 属性,其属性值为 \(o\) 。
每一个三元组都可以通过图(graph)来表示,具体如下图:
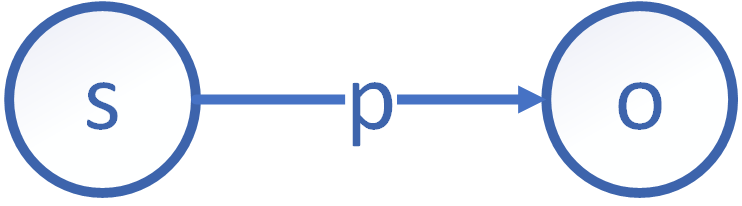
存储方式及其结构
文件存储(序列化)
当数据以文件的形式存储时,RDF 有如下几种序列化格式
RDF/XML
RDF/XML 是最古老的格式,最初出现在 1999 年 RDF 规格说明中。顾名思义,这种方式采取了与 XML 类似的结构存储数据单元(也就是一个三元组)。一个简单的例子如下:
1 | <!-- 本例来自书籍《Learning SPARQL》,详见参考资料(下同) --> |
通过 RDF/XML 格式存储时,其文件后缀名为
.rdf。文件中,所有数据由<rdf:RDF> 和
</rdf:RDF> 包裹,并且在 <rdf:RDF>
属性中定义了前缀(prefix)。
前缀 prefix
RDF 是在 Semantic Web 的背景下提出的,而 Semantic Web
要求在全网下能够唯一标识一个资源,故其采用了 URI
作为资源的唯一标记。URI 一般较为冗长,而定义前缀
,可以减少数据单元中冗长的书写,从而突出数据的重点;当处于不同的前缀中时,数据资源也不会因同名而相互冲突。由于第二点的优势,
前缀又被称作名称空间(namespace)。
每一个数据单元的主语为 rdf:Description 中
rdf:about 属性的值;rdf:Description
子结点标签则代表了数据单元的谓语;宾语可以是
rdf:Description 子结点标签中的纯文字,也可以是子结点标签
rdf:resource 属性所设定的 URI 值。
由于 XML 受限的表达性、RDF/XML 数据文件解析困难等原因,RDF/XML 并没有流行开来。
N3
N3 是 Notation 3 的缩写,它是 RDF 序列化的另一种格式。这种格式继承了 RDF/XML 的优势,尝试改进并弥补了 RDF/XML 部分不足。下面是一个用 N3 格式存储的 RDF 数据:
1 | # The hash symbol is the comment delimiter in n3. |
通过 N3 格式存储时,其文件后缀名为 .n3。与 RDF/XML
格式类似,N3 使用三元组来声明前缀。这个三元组中, @prefix
为主语,<prefix name>:
为谓语,<uri>
则为宾语,并且用英文句号作为三元组的结束标记。在声明完前缀之后,便可以接着以三元组的形式存储数据。例如,第
8 至 9 行为一个三元组,其主语为
<http://www.w3.org/People/Berners-Lee/card#i>,谓语为
v:title,宾语为
"Director"。该三元组说明,由主语标识的资源(此例为人)的头衔为
Director。第 11 至 13 行为第 2 、3 个三元组,分别表示由
<urn:isbn:006251587X> 所标识的书籍的作者是
<http://www.w3.org/People/Berners-Lee/card#i>
这个人;这本书的书名为 "Weaving the Web" 。
N3中的 .、;、,
.代表三元组的结束;代表下一个三元组与当前三元组拥有相同的主语,代表下一个三元组与当前三元组拥有相同的主语和谓语
Turtle
Turtle 是另一种 RDF 序列化的格式,并且使用十分广泛。下面是一个例子:
1 | # filename: ex002.ttl |
Turtle 格式与 N3 很类似,这里不再介绍。
RDFa
RDFa 是另一个受到用户们喜爱的 RDF 序列化格式。RDFa 不仅仅能以 XML 的格式存储,更强大的是其也能嵌入到 HTML 文件中。这使得 SPARQL 等查询工具能够轻松地从中获得以三元组形式存储的数据。下面展示了一个具体的例子:
如果你有一个 HTML 文件,其中有下面一段代码:
1 | <p> |
如果将 RDFa 嵌入其中,那么可以这么写:
1 | <p vocab="http://schema.org/" typeof="Person"> |
数据库存储
除了文件序列化存储方式,RDF 数据亦可存储在数据库中。数据库中 RDF 的存储结构通常由数据库管理系统决定。这里先搁置一边。
其他概念
数据类型
根据上一节的例子,我们发现 RDF 中主要有两类数据,一类为 URI ,另一类为字符串。尽管很多处理 RDF 数据的工具能够根据字符串数据推测数据类型,但仍然建议你在数据中指明各个数据的类型。
没有双引号的字符串的类型推断
当你省略了字符串的双引号,那么处理 RDF 数据的工具将认为该数据类型要么是布尔量(真或假),要么是数字。
在 Turtle
格式中,在数据后面加上两个脱字符(^),并指明标定数据类型的
URI(可使用前缀缩写表示,也可以使用完整的 URI
表示),就可以手动指定数据类型。具体的例子如下(第 7 至 10 行):
1 | # filename: ex033.ttl |
在 RDF/XML 格式中,数据类型由数据标签中 rdf:datatype
属性值所确定(第 8 至 15 行):
1 | <!-- filename: ex035.rdf --> |
语言标记、标签
@lang
RDF
支持国际化,即对于同一个数据,有针对不同语言的不同表示。其一般格式为数据@语言缩写(语言缩写参考了
ISO 639 以及 ISO 3166-1)。
1 | # filename: ex037.ttl |
rdfs:label、rdfs:comment
rdfs:label、rdfs:comment 是 RDF
中非常重要的两个属性名。rdfs:label
通常用来以方便人阅读的名称指代资源,rdfs:comment
通常用来更细节地描述资源。这两个属性值会加深我们对相关资源的理解。
P.S. 在 W3C SKOS 标准下,有两个相关的属性,分别是
skos:prefLabel(代表偏好标签) 和
skos:altLabel(代表替代标签)。
空结点及其作用
在实际情况下,有很多数据是复合数据,即该数据可以分解为更小的数据项(小数据项并不可再分)。例如,地址信息就可以分解为国家、省份、城市、区县、街道、邮编等数据项。那么,如何在 RDF 中表示这样的数据呢?这就需要引入一个独特的结点——空结点。
具体的,空结点将作为联系复合数据属性与各个小数据项之间的桥梁:一是作为复合数据属性(谓语)的属性值(宾语),二是作为小数据项谓语的主语。举个书上的例子你就能理解了(其中
_:b1 为空结点):
1 | # filename: ex041.ttl |
由此可知,空结点的一般格式为 _:<空结点名称>
有时,Turtle 和 SPARQL
也使用方括号([])代表空结点。
Named Graphs
和空结点类似,Named Graphs 也可以用来将一些相关的三元组组合在一起。而与之不同的是,Named Graphs 更加强大——可进一步赋予其元数据(metadata)。这种特性使得 Named Graphs 在某些应用场景下有着独特的优势。
RDF 模式和 OWL
在程序设计中,经常会考虑复用问题,因为复用可以有效提高软件开发效率。十分幸运,RDF 也提供了复用方案,即 RDF 模式和 OWL(Web Ontological Language)。
RDF 模式使用一系列三元组描述了有关该类资源的事实(如指明
rdf:type、 rdfs:label
、rdf:comment 等)。这些事实也被称为该类资源的元数据。
下面是两个具体的例子:
1 | # filename: ex042.ttl |
1 | # filename: ex043.ttl |
在元数据中,有两个非常特殊的属性 rdfs:domain 和
rdfs:range :
rdfs:domain:该属性的值是rdfs:domain所在三元组主语的类别rdfs:range:该属性的值是rdfs:range所在三元组宾语的类别
依照这样的关系,在 RDF 中,我们能推理出很多隐藏在图中的结论。
然而,RDF 模式还是有限的,它无法描述类之间的联系。要解决这个问题,便引入了 OWL。
下面,我将结合书上的例子说明:
1 | # filename: ex046.ttl |
其中,ab:spouse 的 rdf:type 为
SymmetricProperty
,表示这个属性是对称的。在本例中,ab:i0432 的配偶是 ab:i9771
,那么根据对称属性的性质推理,我们可以得到,ab:i9771 的配偶则是 ab:i0432
。又如,ab:doctor 的 owl:inverseOf 的值为
ab:patient,则在本例中,由于 ab:i8301 有一位病人
ab:i9771,则 ab:i9771 有一位医生 ab:i8301。
总结
本文主要介绍了有关 RDF 的基本概念、格式、存储结构和其他一些细节。最后,对全文做一个简单的总结。
- RDF 全称 Resource Description Framework(资源描述框架),是一种数据模型,它提供了一种独特的结构来存储数据文件。
- RDF 数据单元是一个三元组 \((s,\ p,\ o)\) ,其中 \(s\) 代表 subject(主语),\(p\) 代表 predicate(谓语), \(o\) 代表 object(宾语)。每一个三元组都可以陈述这样一个事实:一个由 \(s\) 唯一标记的资源实体拥有 \(p\) 属性,其属性值为 \(o\) 。
- RDF 数据的存储主要有两种:文件序列化存储(包括 RDF/XML、Turtle、RDFa 等格式)、数据库存储。
- RDF 中的数据类型指定一般可表示为
数据^^<数据类型URI>。 - RDF 支持国际化,一般格式为
数据@语言缩写。 rdfs:label、rdfs:comment是 RDF 中非常重要的两个属性名。rdfs:label通常用来以方便人阅读的名称指代资源,rdfs:comment通常用来更细节地描述资源。- RDF 中,空结点可用来连接数据。
- Named Graphs 可用于组合三元组数据,并可赋予一些元数据。
- RDF 模式和 OWL 可用于 RDF 资源、属性的复用。RDF 模式中可定义类、属性的事实元数据,并提供给外界使用,达到复用的目的;OWL 则扩展了 RDF 模式的表达性,从而支持描述类之间的关系。
参考资料
- Bob DuCharme. Learning SPARQL: querying and updating with SPARQL 1.1
- Juan Sequeda. Introduction to: RDFa.
- Juan Sequeda. Introduction to: Ontologies.